Make Your Deepseek China Ai A Reality
페이지 정보
작성자 Gregg 작성일25-02-07 17:20 조회2회 댓글0건관련링크
본문
 HuggingFaceFW: This is the "high-quality" cut up of the latest well-acquired pretraining corpus from HuggingFace. The break up was created by coaching a classifier on Llama three 70B to identify academic fashion content. HelpSteer2 by nvidia: It’s rare that we get access to a dataset created by one among the big data labelling labs (they push pretty onerous against open-sourcing in my expertise, in order to guard their enterprise mannequin). Integrate user suggestions to refine the generated check knowledge scripts. The company mentioned it experienced some outages on Monday affecting person signups. The latest debut of the Chinese AI mannequin, DeepSeek R1, has already prompted a stir in Silicon Valley, prompting concern among tech giants resembling OpenAI, Google, and Microsoft. "This is like being in the late nineties or even right across the 12 months 2000 and making an attempt to foretell who could be the main tech corporations, or the main web firms in 20 years," said Jennifer Huddleston, a senior fellow on the Cato Institute. Miles Brundage, an AI policy professional who not too long ago left OpenAI, has advised that export controls may still sluggish China down on the subject of running more AI experiments and constructing AI agents.
HuggingFaceFW: This is the "high-quality" cut up of the latest well-acquired pretraining corpus from HuggingFace. The break up was created by coaching a classifier on Llama three 70B to identify academic fashion content. HelpSteer2 by nvidia: It’s rare that we get access to a dataset created by one among the big data labelling labs (they push pretty onerous against open-sourcing in my expertise, in order to guard their enterprise mannequin). Integrate user suggestions to refine the generated check knowledge scripts. The company mentioned it experienced some outages on Monday affecting person signups. The latest debut of the Chinese AI mannequin, DeepSeek R1, has already prompted a stir in Silicon Valley, prompting concern among tech giants resembling OpenAI, Google, and Microsoft. "This is like being in the late nineties or even right across the 12 months 2000 and making an attempt to foretell who could be the main tech corporations, or the main web firms in 20 years," said Jennifer Huddleston, a senior fellow on the Cato Institute. Miles Brundage, an AI policy professional who not too long ago left OpenAI, has advised that export controls may still sluggish China down on the subject of running more AI experiments and constructing AI agents.
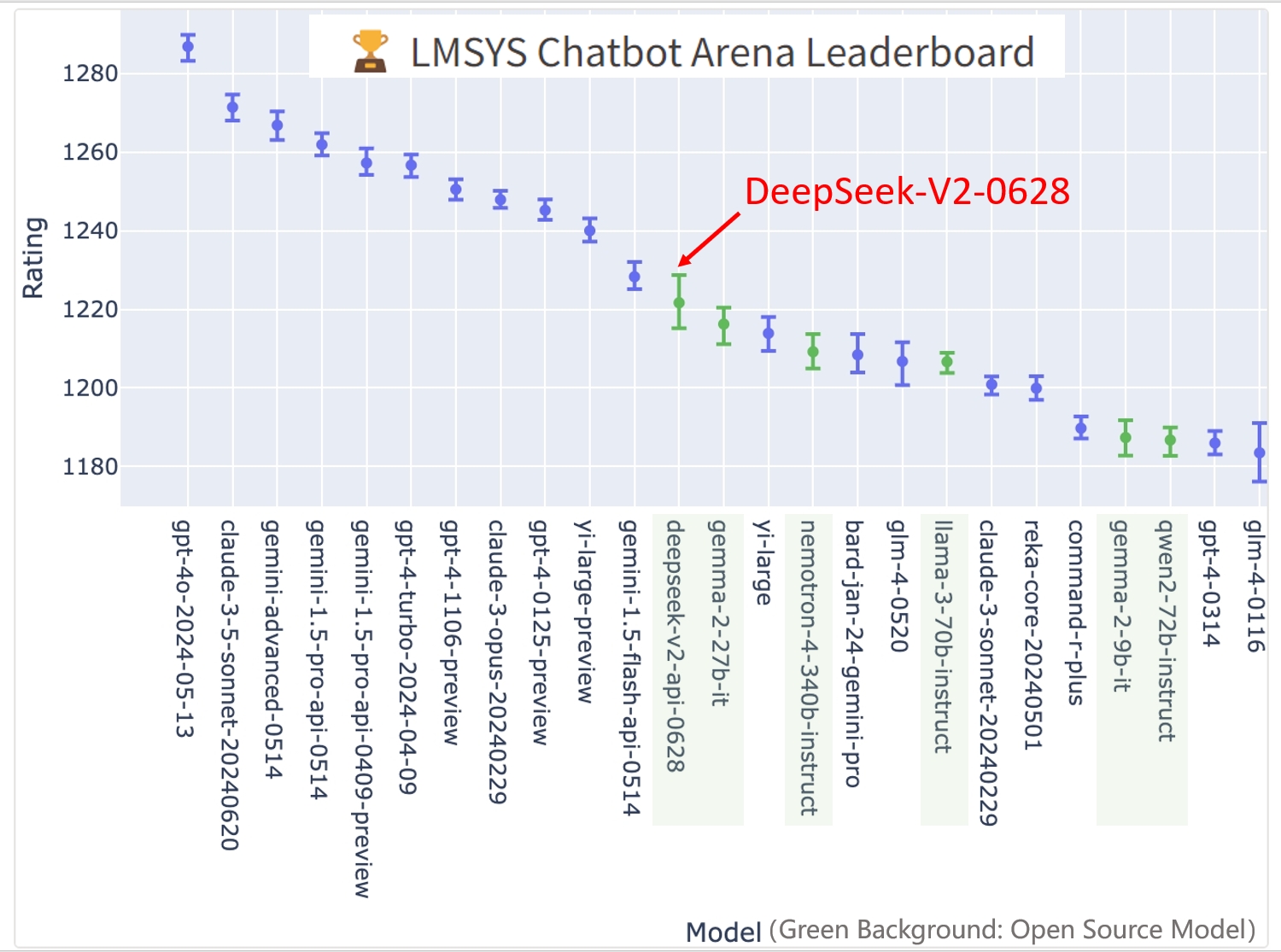 It’s nice to have extra competitors and peers to learn from for OLMo. We thought it too and after performing some research and utilizing the software, we've an answer for you. Yes, when you've got a set of N models, it is sensible that you need to use related methods to mix them utilizing varied merge and selection strategies such that you simply maximize scores on the exams you might be utilizing. Given the amount of fashions, I’ve broken them down by class. Two API fashions, Yi-Large and GLM-4-0520 are still forward of it (however we don’t know what they're). Mistral-7B-Instruct-v0.3 by mistralai: Mistral remains to be enhancing their small fashions whereas we’re ready to see what their strategy replace is with the likes of Llama 3 and Gemma 2 on the market. The US owned Open AI was the chief within the AI business, nevertheless it can be attention-grabbing to see how things unfold amid the twists and turns with the launch of the brand new satan in city Deepseek R-1. That is a website I count on things to develop on.
It’s nice to have extra competitors and peers to learn from for OLMo. We thought it too and after performing some research and utilizing the software, we've an answer for you. Yes, when you've got a set of N models, it is sensible that you need to use related methods to mix them utilizing varied merge and selection strategies such that you simply maximize scores on the exams you might be utilizing. Given the amount of fashions, I’ve broken them down by class. Two API fashions, Yi-Large and GLM-4-0520 are still forward of it (however we don’t know what they're). Mistral-7B-Instruct-v0.3 by mistralai: Mistral remains to be enhancing their small fashions whereas we’re ready to see what their strategy replace is with the likes of Llama 3 and Gemma 2 on the market. The US owned Open AI was the chief within the AI business, nevertheless it can be attention-grabbing to see how things unfold amid the twists and turns with the launch of the brand new satan in city Deepseek R-1. That is a website I count on things to develop on.
Adapting that bundle to the precise reasoning area (e.g., by immediate engineering) will probably additional increase the effectiveness and reliability of the reasoning metrics produced. Feeding the argument maps and reasoning metrics back into the code LLM's revision course of may additional increase the general efficiency. DeepSeek's developers opted to release it as an open-source product, which means the code that underlies the AI system is publicly available for different companies to adapt and build upon. 7b by m-a-p: Another open-supply mannequin (not less than they include knowledge, I haven’t looked on the code). Qwen 2.5-Max is a big language mannequin from Alibaba. Consistently, the 01-ai, DeepSeek AI, and Qwen groups are delivery great models This DeepSeek model has "16B complete params, 2.4B energetic params" and is trained on 5.7 trillion tokens. DeepSeek-V2-Lite by deepseek-ai: Another great chat model from Chinese open mannequin contributors. There are not any signs of open models slowing down. There isn't a explanation of what "p" stands for, what m stands and so on. However, limited by mannequin capabilities, associated purposes will gradually purchase full skills.
However, above 200 tokens, the opposite is true. Google reveals every intention of placing a variety of weight behind these, which is implausible to see. Google unveils invisible ‘watermark’ for AI-generated textual content. This interface empowers customers with a consumer-pleasant platform to engage with these fashions and effortlessly generate text. DeepSeek launched its AI language model in November 2023 as an open-source product-permitting users to obtain and run it regionally on their own computers. But you'll be able to run it in a distinct mode than the default. PRC can modernize their navy; they only shouldn’t be doing it with our stuff. 3.6-8b-20240522 by openchat: These openchat models are actually common with researchers doing RLHF. They're sturdy base models to do continued RLHF or reward modeling on, and here’s the most recent model! It present strong results on RewardBench and downstream RLHF performance. This model reaches similar efficiency to Llama 2 70B and makes use of less compute (solely 1.Four trillion tokens). Chinese startup like DeepSeek to build their AI infrastructure, mentioned "launching a aggressive LLM mannequin for client use cases is one thing…
In case you have almost any inquiries relating to where along with how to employ شات DeepSeek, you are able to call us from our own page.
댓글목록
등록된 댓글이 없습니다.





