7 Days To A Better Deepseek
페이지 정보
작성자 Gladis 작성일25-02-10 08:03 조회6회 댓글0건관련링크
본문
 To implement MTP, DeepSeek V3 adopts multiple model, every consisting of a bunch of Transformer layers. Also, we can use the MTP module to implement a speculative decoding approach to doubtlessly pace up the generation process much more. DeepSeek has decided to open-supply the V3 model underneath the MIT license, which signifies that builders can have free entry to its weights and use it for their own functions, even for industrial use. Download the model version that you like and then put the weights inside of /path/to/DeepSeek-V3 folder. There are two mannequin weights out there on HuggingFace: the bottom model (only after the pre-coaching part) and the chat model (after submit-training phase). The best approach to try out DeepSeek V3 is through the official chat platform of DeepSeek. Quirks embody being way too verbose in its reasoning explanations and using a lot of Chinese language sources when it searches the online. Provide a passing take a look at through the use of e.g. Assertions.assertThrows to catch the exception. Additionally, the efficiency of DeepSeek V3 has been compared with different LLMs on open-ended generation duties using GPT-4-Turbo-1106 as a choose and size-managed win fee because the metric. Although its efficiency is already superior in comparison with other state-of-the-artwork LLMs, research means that the efficiency of DeepSeek V3 might be improved even more in the future.
To implement MTP, DeepSeek V3 adopts multiple model, every consisting of a bunch of Transformer layers. Also, we can use the MTP module to implement a speculative decoding approach to doubtlessly pace up the generation process much more. DeepSeek has decided to open-supply the V3 model underneath the MIT license, which signifies that builders can have free entry to its weights and use it for their own functions, even for industrial use. Download the model version that you like and then put the weights inside of /path/to/DeepSeek-V3 folder. There are two mannequin weights out there on HuggingFace: the bottom model (only after the pre-coaching part) and the chat model (after submit-training phase). The best approach to try out DeepSeek V3 is through the official chat platform of DeepSeek. Quirks embody being way too verbose in its reasoning explanations and using a lot of Chinese language sources when it searches the online. Provide a passing take a look at through the use of e.g. Assertions.assertThrows to catch the exception. Additionally, the efficiency of DeepSeek V3 has been compared with different LLMs on open-ended generation duties using GPT-4-Turbo-1106 as a choose and size-managed win fee because the metric. Although its efficiency is already superior in comparison with other state-of-the-artwork LLMs, research means that the efficiency of DeepSeek V3 might be improved even more in the future.

MTP might be repurposed during inference to facilitate a speculative decoding strategy. Visualization of MTP approach in DeepSeek V3. Although it is not clearly defined, the MTP model is usually smaller in measurement compared to the principle mannequin (the whole size of the DeepSeek V3 mannequin on HuggingFace is 685B, with 671B from the main model and 14B from the MTP module). After predicting the tokens, both the primary model and MTP modules will use the same output head. However, count on it to be integrated very soon so that you need to use and run the model locally in a straightforward approach. Throughout the coaching section, both the principle mannequin and MTP modules take enter from the identical embedding layer. For example, we will utterly discard the MTP module and use only the main model throughout inference, similar to frequent LLMs. This technique helps to quickly discard the unique assertion when it's invalid by proving its negation.
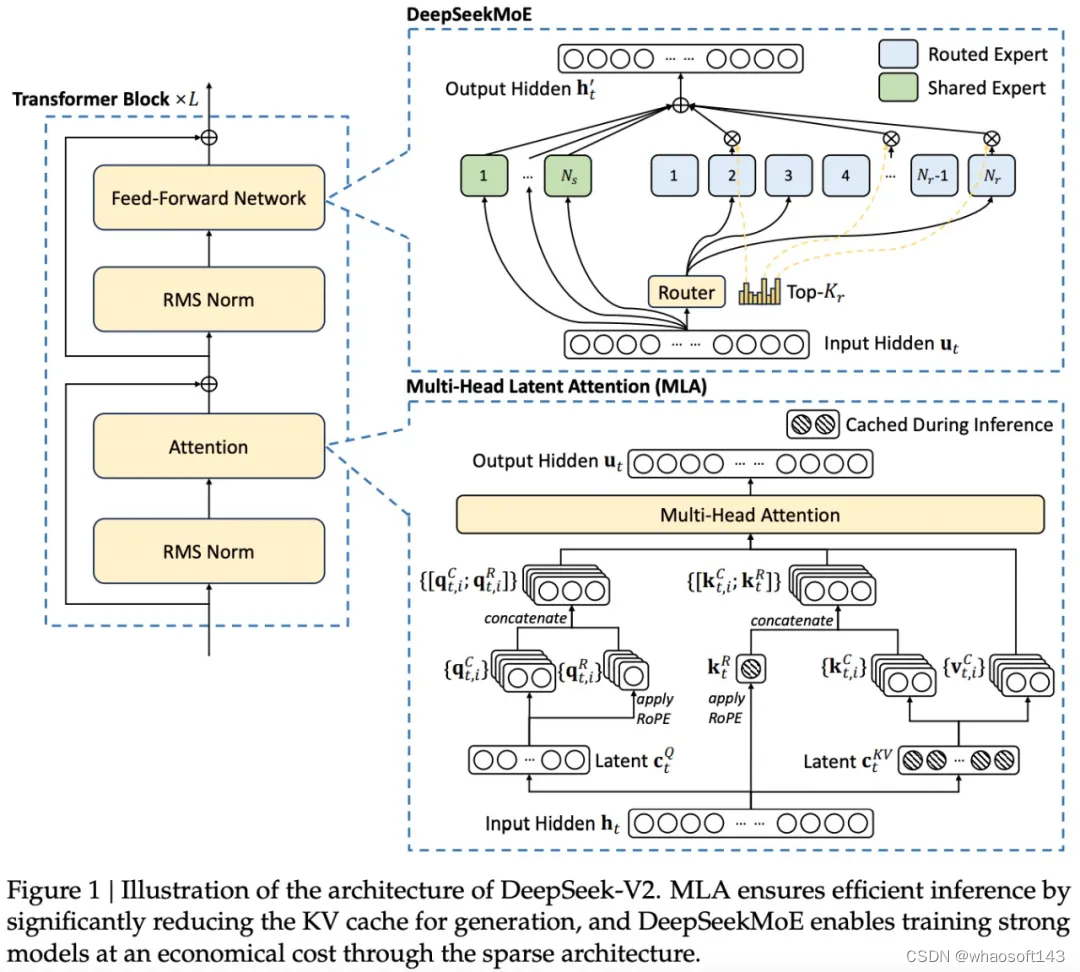
Also, its open-supply nature beneath the MIT license enables the AI neighborhood to construct on its advancements, thus accelerating progress towards AGI. MLA enables us to save KV cache reminiscence and velocity up token technology by compressing the dimension of input representations into their low-rank illustration. MoE speeds up the token generation course of and improves model scalability by activating only sure experts during inference, relying on the task. This course of continues relying on the variety of MTP modules. Yes, the app is accessible totally free, but further premium options might require a subscription depending on the consumer's needs. One of the standout options of DeepSeek’s LLMs is the 67B Base version’s distinctive efficiency in comparison with the Llama2 70B Base, showcasing superior capabilities in reasoning, coding, arithmetic, and Chinese comprehension. The entire modern options mentioned above enabled the DeepSeek V3 mannequin to be skilled rather more cheaply than its closed-source opponents. The mannequin requires vital computing resources for efficient operation, however supplies top quality textual content technology while sustaining full management over knowledge and query processing. Nonetheless, this analysis exhibits that the same data distillation method can also be applied to DeepSeek V3 in the future to additional optimize its efficiency across numerous knowledge domains.
If you loved this posting and you would like to obtain much more info with regards to ديب سيك شات kindly stop by our web-site.
댓글목록
등록된 댓글이 없습니다.





