페이지 정보
작성자 Alisia Kirkby 작성일25-02-23 13:17 조회6회 댓글0건관련링크
본문
 DeepSeek-V2.5 was a pivotal replace that merged and upgraded the DeepSeek V2 Chat and DeepSeek Coder V2 models. For instance, a company prioritizing rapid deployment and support would possibly lean in direction of closed-supply options, while one looking for tailor-made functionalities and value effectivity might find open-supply models extra appealing. DeepSeek, a Chinese AI startup, has made waves with the launch of fashions like DeepSeek-R1, which rival industry giants like OpenAI in performance whereas reportedly being developed at a fraction of the fee. Key on this course of is constructing robust evaluation frameworks that can aid you precisely estimate the performance of the varied LLMs used. 36Kr: But with out two to 3 hundred million dollars, you can't even get to the table for foundational LLMs. It even shows you how they could spin the topics into their advantage. You need the technical abilities to have the ability to handle and adapt the models effectively and safeguard efficiency.
DeepSeek-V2.5 was a pivotal replace that merged and upgraded the DeepSeek V2 Chat and DeepSeek Coder V2 models. For instance, a company prioritizing rapid deployment and support would possibly lean in direction of closed-supply options, while one looking for tailor-made functionalities and value effectivity might find open-supply models extra appealing. DeepSeek, a Chinese AI startup, has made waves with the launch of fashions like DeepSeek-R1, which rival industry giants like OpenAI in performance whereas reportedly being developed at a fraction of the fee. Key on this course of is constructing robust evaluation frameworks that can aid you precisely estimate the performance of the varied LLMs used. 36Kr: But with out two to 3 hundred million dollars, you can't even get to the table for foundational LLMs. It even shows you how they could spin the topics into their advantage. You need the technical abilities to have the ability to handle and adapt the models effectively and safeguard efficiency.
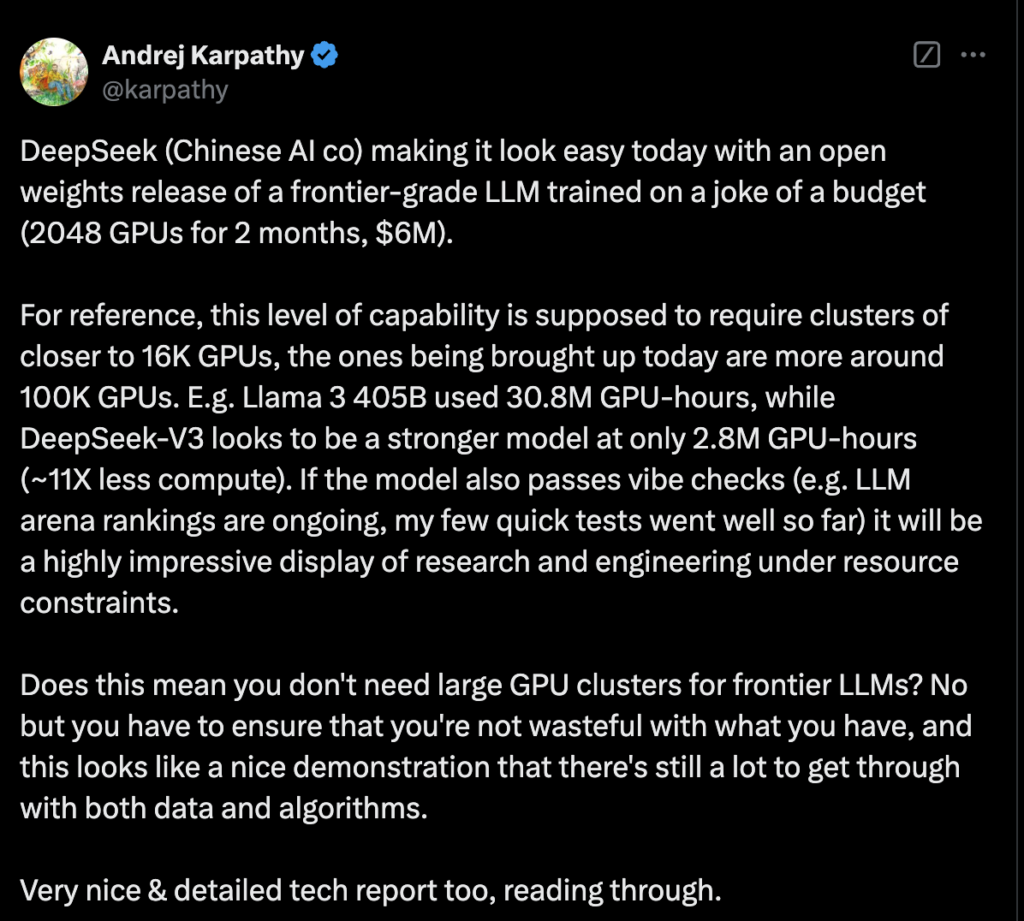
Before discussing four primary approaches to constructing and enhancing reasoning models in the following part, I want to briefly define the DeepSeek R1 pipeline, as described in the DeepSeek R1 technical report. Our two main salespeople had been novices on this industry. Its first mannequin was released on November 2, 2023.2 However the fashions that gained them notoriety in the United States are two most recent releases, V3, a common large language model ("LLM"), and R1, a "reasoning" model. Your entire pre-coaching stage was completed in underneath two months, requiring 2.664 million GPU hours. Assuming a rental price of $2 per GPU hour, this introduced the total coaching value to $5.576 million. Those in search of most control and price efficiency could lean toward open-source models, while these prioritizing ease of deployment and assist should go for closed-supply APIs. Second, while the acknowledged training value for DeepSeek-R1 is impressive, it isn’t directly related to most organizations as media retailers portray it to be.
 Should we prioritize open-supply fashions like DeepSeek-R1 for flexibility, or keep on with proprietary systems for perceived reliability? People have been offering completely off-base theories, like that o1 was simply 4o with a bunch of harness code directing it to cause. It achieved this by implementing a reward system: for objective duties like coding or math, rewards have been given based on automated checks (e.g., working code assessments), whereas for subjective tasks like inventive writing, a reward mannequin evaluated how properly the output matched desired qualities like readability and relevance. Whether you’re a researcher, developer, or an AI enthusiast, DeepSeek offers a powerful AI-driven search engine, coding assistants, and advanced API integrations. Since DeepSeek is open-supply, cloud infrastructure providers are free to deploy the mannequin on their platforms and provide it as an API service. DeepSeek V3 is offered via a web based demo platform and API service, providing seamless access for various purposes.
Should we prioritize open-supply fashions like DeepSeek-R1 for flexibility, or keep on with proprietary systems for perceived reliability? People have been offering completely off-base theories, like that o1 was simply 4o with a bunch of harness code directing it to cause. It achieved this by implementing a reward system: for objective duties like coding or math, rewards have been given based on automated checks (e.g., working code assessments), whereas for subjective tasks like inventive writing, a reward mannequin evaluated how properly the output matched desired qualities like readability and relevance. Whether you’re a researcher, developer, or an AI enthusiast, DeepSeek offers a powerful AI-driven search engine, coding assistants, and advanced API integrations. Since DeepSeek is open-supply, cloud infrastructure providers are free to deploy the mannequin on their platforms and provide it as an API service. DeepSeek V3 is offered via a web based demo platform and API service, providing seamless access for various purposes.
HuggingFace reported that DeepSeek fashions have more than 5 million downloads on the platform. If you don't have a strong computer, I recommend downloading the 8b model. YaRN is an improved model of Rotary Positional Embeddings (RoPE), a kind of place embedding that encodes absolute positional information utilizing a rotation matrix, with YaRN effectively interpolating how these rotational frequencies within the matrix will scale. Each trillion tokens took 180,000 GPU hours, or 3.7 days, utilizing a cluster of 2,048 H800 GPUs. Adding 119,000 GPU hours for extending the model’s context capabilities and 5,000 GPU hours for final superb-tuning, the entire coaching used 2.788 million GPU hours. It’s a practical means to spice up mannequin context size and enhance generalization for longer contexts without the necessity for costly retraining. The result's DeepSeek-V3, a big language model with 671 billion parameters. The energy around the world as a result of R1 becoming open-sourced, incredible.
댓글목록
등록된 댓글이 없습니다.





