Dreaming Of Deepseek
페이지 정보
작성자 Franklin Shoema… 작성일25-02-23 13:22 조회3회 댓글0건관련링크
본문
 I see lots of the improvements made by DeepSeek as "obvious in retrospect": they're the type of innovations that, had somebody requested me upfront about them, I would have mentioned were good ideas. 36Kr: There's a form of spiritual reward in that. 36Kr: Are such folks straightforward to find? Liang Wenfeng: When doing something, experienced individuals might instinctively inform you how it needs to be completed, but these with out experience will discover repeatedly, think seriously about how you can do it, and then find a solution that fits the current reality. A principle at High-Flyer is to take a look at capability, not expertise. 36Kr: In revolutionary ventures, do you assume experience is a hindrance? If you assume you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response workforce. 36Kr: What are the essential criteria for recruiting for the LLM team? It's presently unclear whether DeepSeek's deliberate open source release can even include the code the team used when training the mannequin. DeepSeek R1 is right here: Performance on par with OpenAI o1, however open-sourced and with absolutely open reasoning tokens.
I see lots of the improvements made by DeepSeek as "obvious in retrospect": they're the type of innovations that, had somebody requested me upfront about them, I would have mentioned were good ideas. 36Kr: There's a form of spiritual reward in that. 36Kr: Are such folks straightforward to find? Liang Wenfeng: When doing something, experienced individuals might instinctively inform you how it needs to be completed, but these with out experience will discover repeatedly, think seriously about how you can do it, and then find a solution that fits the current reality. A principle at High-Flyer is to take a look at capability, not expertise. 36Kr: In revolutionary ventures, do you assume experience is a hindrance? If you assume you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response workforce. 36Kr: What are the essential criteria for recruiting for the LLM team? It's presently unclear whether DeepSeek's deliberate open source release can even include the code the team used when training the mannequin. DeepSeek R1 is right here: Performance on par with OpenAI o1, however open-sourced and with absolutely open reasoning tokens.
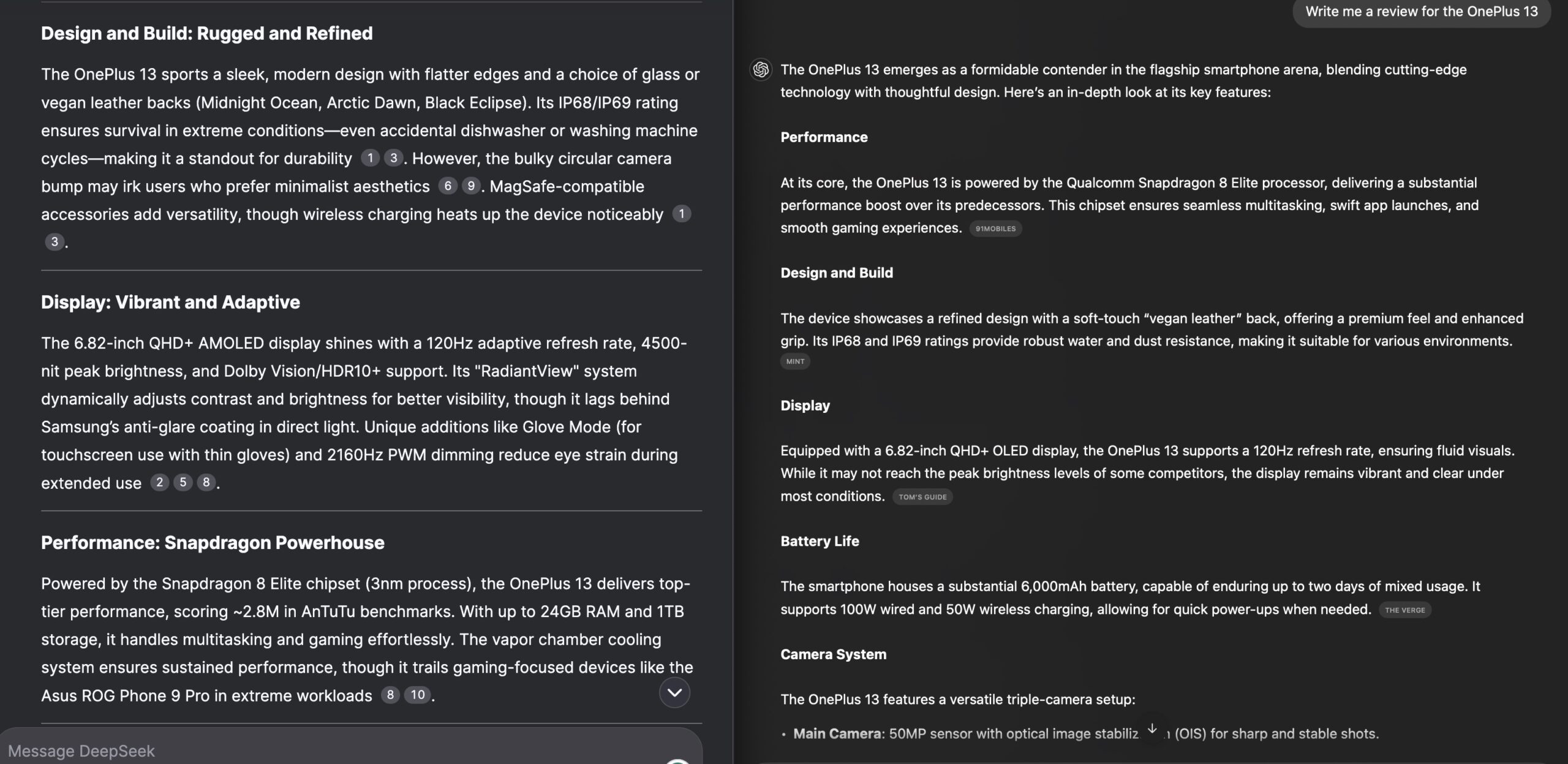
Encoding: The tokens are passed by means of a transformer-based mostly architecture to seize contextual data. We pretrained DeepSeek-V2 on a diverse and excessive-quality corpus comprising 8.1 trillion tokens. On January 27, 2025, major tech corporations, including Microsoft, Meta, Nvidia, and Alphabet, collectively lost over $1 trillion in market value. On January 27, 2025, the global AI panorama shifted dramatically with the launch of DeepSeek, a Chinese AI startup has rapidly emerged as a disruptive power in the industry. Chen, Caiwei (24 January 2025). "How a high Chinese AI model overcame US sanctions". How open is open? Nvidia is touting the performance of Free DeepSeek Ai Chat’s open source AI fashions on its just-launched RTX 50-sequence GPUs, claiming that they'll "run the DeepSeek household of distilled fashions quicker than something on the Pc market." But this announcement from Nvidia is perhaps somewhat lacking the purpose. The overall dimension of DeepSeek-V3 fashions on Hugging Face is 685B, which incorporates 671B of the main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. A subsequent-technology reasoning model that runs domestically in your browser with WebGPU acceleration. The thoughts generated by a reasoning mannequin are now separated into thought segments in the response, so you can select whether or not to make use of them or not.
While R1-Zero is just not a prime-performing reasoning model, it does reveal reasoning capabilities by generating intermediate "thinking" steps, as shown within the determine above. The company leverages a singular method, specializing in resource optimization while sustaining the excessive efficiency of its models. While Goldman Sachs pegs a 20-basis-point to 30-foundation-level boost to China's GDP over the long term - by 2030 - it expects the country's economic system to start out reflecting the optimistic impact of AI adoption from subsequent yr itself as AI-driven automation improves productivity. Improves search outcomes by understanding the meaning of queries relatively than simply matching keywords. Lower coaching loss means extra correct results. We don't intentionally keep away from skilled individuals, but we focus more on ability. Liang Wenfeng: Unlike most companies that target the volume of consumer orders, our gross sales commissions are usually not pre-calculated. Take the gross sales position as an example. More often, it's about main by instance. To boost its reliability, we construct preference knowledge that not only supplies the final reward but also includes the chain-of-thought leading to the reward. Normalization: The final embeddings are sometimes normalized to improve cosine similarity calculations.
 8 GPUs are required. For the MoE part, every GPU hosts just one knowledgeable, and sixty four GPUs are liable for internet hosting redundant consultants and shared experts. We introduce DeepSeek-V2, a powerful Mixture-of-Experts (MoE) language mannequin characterized by economical coaching and efficient inference. The usage of DeepSeek-V2 Base/Chat models is subject to the Model License. Overall, when examined on 40 prompts, DeepSeek was found to have a similar power effectivity to the Meta mannequin, however DeepSeek tended to generate for much longer responses and therefore was discovered to make use of 87% extra power. By dividing duties amongst specialised computational "experts," DeepSeek minimizes energy consumption and reduces operational prices. We don't have KPIs or so-called duties. This performance highlights the model’s effectiveness in tackling dwell coding tasks. By leveraging small but numerous consultants, DeepSeekMoE makes a speciality of information segments, reaching performance ranges comparable to dense fashions with equal parameters however optimized activation. Developers can modify and run the fashions regionally, not like proprietary AI fashions reminiscent of ChatGPT, which have restricted access.
8 GPUs are required. For the MoE part, every GPU hosts just one knowledgeable, and sixty four GPUs are liable for internet hosting redundant consultants and shared experts. We introduce DeepSeek-V2, a powerful Mixture-of-Experts (MoE) language mannequin characterized by economical coaching and efficient inference. The usage of DeepSeek-V2 Base/Chat models is subject to the Model License. Overall, when examined on 40 prompts, DeepSeek was found to have a similar power effectivity to the Meta mannequin, however DeepSeek tended to generate for much longer responses and therefore was discovered to make use of 87% extra power. By dividing duties amongst specialised computational "experts," DeepSeek minimizes energy consumption and reduces operational prices. We don't have KPIs or so-called duties. This performance highlights the model’s effectiveness in tackling dwell coding tasks. By leveraging small but numerous consultants, DeepSeekMoE makes a speciality of information segments, reaching performance ranges comparable to dense fashions with equal parameters however optimized activation. Developers can modify and run the fashions regionally, not like proprietary AI fashions reminiscent of ChatGPT, which have restricted access.
If you have any thoughts concerning wherever and how to use Deepseek AI Online chat, you can speak to us at our own web-site.
댓글목록
등록된 댓글이 없습니다.





